Linux硬链接和软链接
硬链接
先来看看 ln 默认创建的硬链接,由于 Linux 下的文件是通过索引节点(Inode)来识别文件,在 Linux 的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Number)。
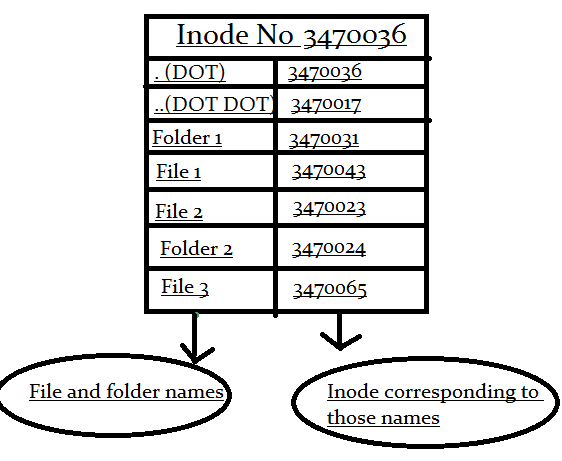
在 Linux 中,多个文件名指向同一索引节点是存在的,所以硬连接指通过索引节点来进行的连接,即每一个硬链接都是一个指向对应区域的文件。 我们这里创建一个文件 foo.txt 然后建立一个它的硬链接看看:
➜ vim foo.txt
➜ cat foo.txt
LeetCode
➜ ln foo.txt bar.txt # 这一步是用来创建硬链接
➜ ls -li
total 6552
6817859 -rw-rw-r--. 2 Nova Nova 9 Sep 19 15:59 bar.txt
6817859 -rw-rw-r--. 2 Nova Nova 9 Sep 19 15:59 foo.txt
前面的 6817859 是文件的 inode,可以简单把它想成 C 语言中的指针,它指向了物理硬盘的一个区块,事实上文件系统会维护一个引用计数,只要有文件指向这个区块,它就不会从硬盘上消失,这里我们会发现,这两个文件拥有相同的 inode,通过查看文件内容也会发现是同一个文件:
➜ cat bar.txt
LeetCode
硬链接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬链接到重要文件,以防止“误删”的功能,由于对应该目录的索引节点有一个以上的连接,假设我们删除了原始的 foo.txt 文件:
➜ rm -f foo.txt
➜ cat bar.txt
LeetCode
此时文件的内容依然存在,所以只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个链接被删除后,文件的数据块及目录的连接才会被释放,也就是说,文件才会被真正删除
软链接
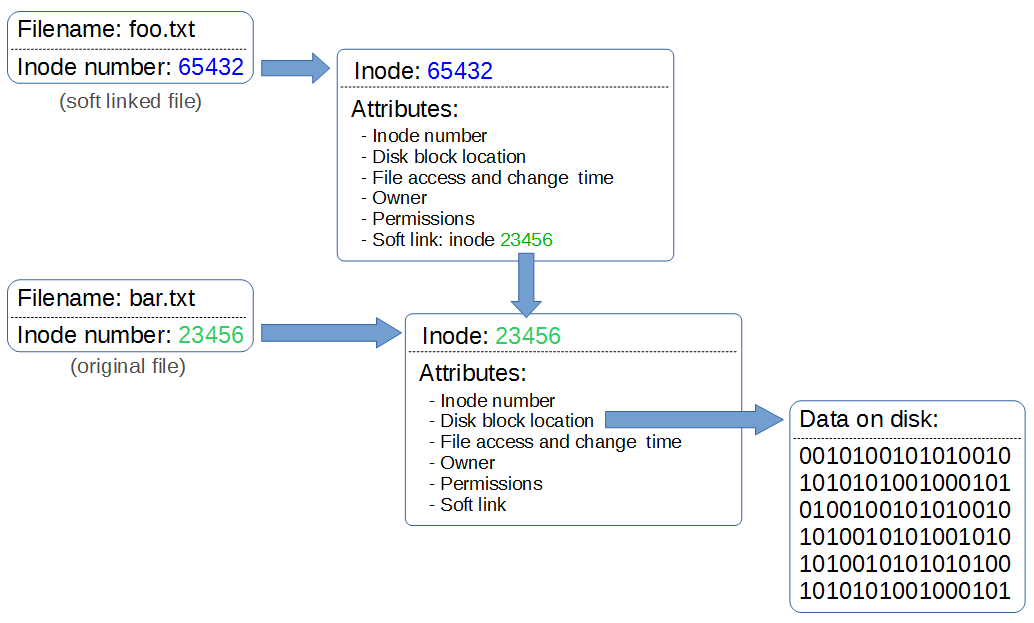
软链接又叫符号链接,这个文件包含了另一个文件的路径名,例如在上图中,foo.txt 就是 bar.txt 的软连接,bar.txt 是实际的文件,foo.txt 包含的是对于 bar.txt 的 inode 的记录。
软连接可以是任意文件或目录,可以链接不同文件系统的文件,在对符号文件进行读或写操作的时候,系统会自动把该操作转换为对源文件的操作,但删除链接文件时,系统仅仅删除链接文件,而不删除源文件本身,这一点类似于 Windows 操作系统下的快捷方式。
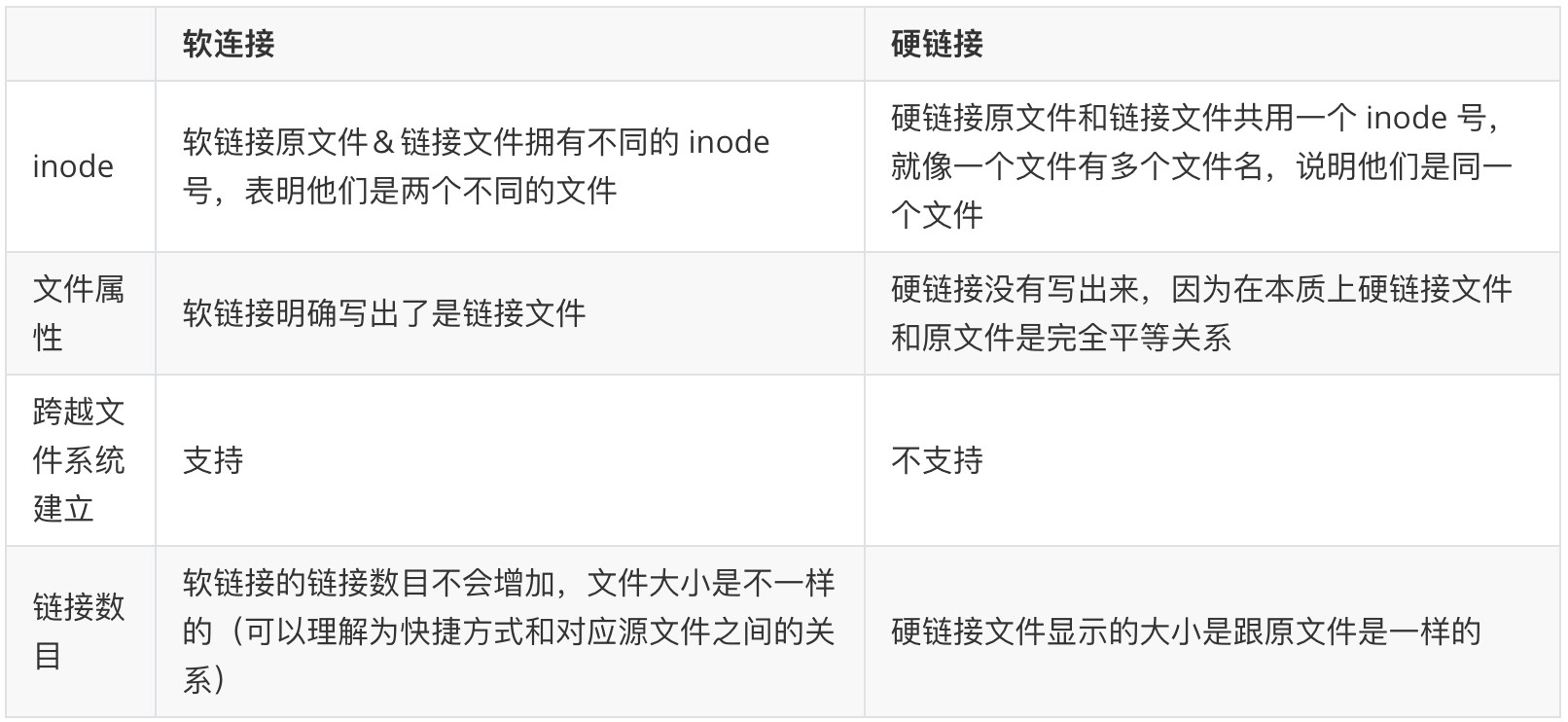
软链接和硬链接的区别
在有了上面的知识后我们就可以简要地回答面试中的问题了:
软链接和硬链接的区别是什么? 我们来总结一下:
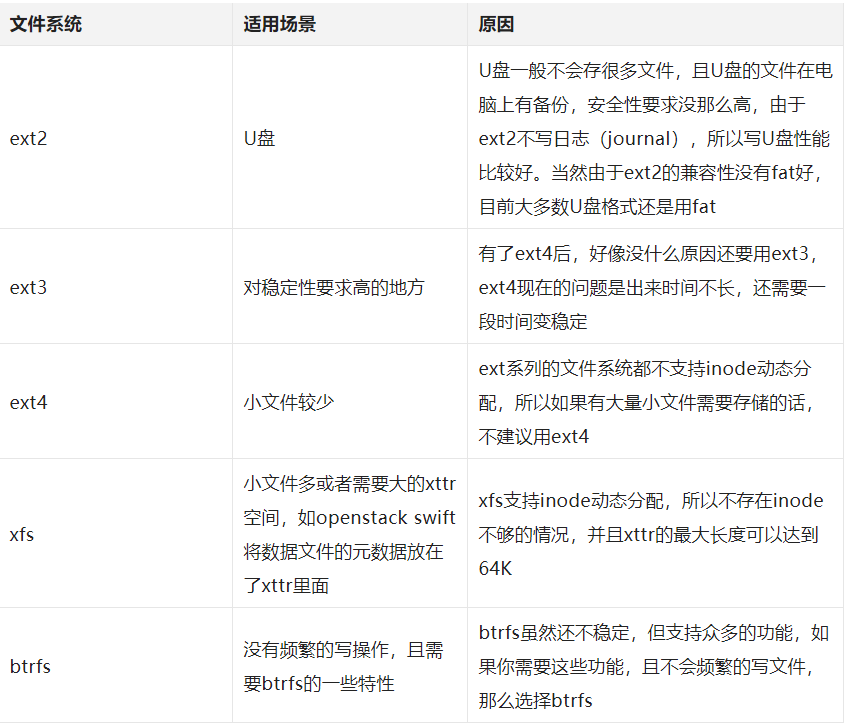
Linux下常见文件系统对比
ext2
ext的优点是比较简单,文件比较少时性能较好,比较适合文件少的场景,主要缺点如下
inode的数量是固定不变的,在格式化分区的时候可以指定inode和数据块所占空间的比例,但一旦格式化好,后续就没法再改变了 当块大小为4K时,单个文件大小不能超过2TB,分区大小不能超过16TB(目前硬盘大小一般都只有几TB,所以也不是什么大问题,)
- 一个目录下最多只能有32000个子目录
- 由于目录里面存储的文件和子目录都是以线性方式来组织的,所以遍历目录效率不高,尤其当目录下文件个数达到10K以上规模的时候,速度会明显的变慢
- 当底层的磁盘分区空间变大时(使用LVM时很常见),ext2没法动态的扩展来使用增加的空间
- 没有日志(Journal)功能,所以数据的安全性不高
ext3
ext3在ext2的基础上实现了下面几个功能,其它的都保持不变,即ext2的缺点ext3也有
- 支持日志(Journal)功能,数据的安全性较ext2有很大的提高
- 当底层的分区空间变大时,ext3可以自动扩展来使用增加的空间
- 使用HTree来组织目录里面的文件和子目录,使目录下的文件和子目录数不再受性能限制(数量超过10K也不会有性能问题)
ext4
ext4借鉴了当前成熟的一些文件系统技术,在ext3上增加了一些功能,并且对性能做了一些改进,主要变化如下 当块大小为4K时,支持的最大文件和最大分区大小分别达到了16TB和1EB 不再受32000个子目录数的限制,支持不限数量的子目录个数 支持Extents,提高了大文件的操作性能 内部实现上支持一次分配多个数据块,较ext3的性能有所提高
- 支持延时分配(即支持fallocate函数)(fallocate是libc的函数,在不支持该功能的文件系统上,libc会创建一个占用磁盘空间文件)
- 支持在线快速扫描
- 支持在线碎片整理(单个文件或者整个分区)
- 日志(Journal)支持校验码(checksum),数据的安全性进一步提高
- 支持无日志(No Journaling)模式(ext3不支持该功能),这样就和ext2一样,消除了写日志对性能的影响
- 支持纳秒级的时间戳
- 记录了文件的创建时间,由于相关的应用层工具还不支持,所以只能通过debug的方式看到文件的创建时间
这里是一个查看文件/etc/fstab创建时间的例子(文件存在/dev/sda1分区上):
dev@ubuntu:~$ ls -i /etc/fstab
10747906 /etc/fstab
dev@ubuntu:~$ sudo debugfs -R 'stat <10747906>' /dev/sda1
Inode: 10747906 Type: regular Mode: 0644 Flags: 0x80000 Links: 1 Blockcount: 8 ctime: 0x5546dc54:6e6bc80c -- Sun May 3 22:41:24 2015
atime: 0x55d1b014:8bcf7b44 -- Mon Aug 17 05:57:40 2015
mtime: 0x5546dc54:6e6bc80c -- Sun May 3 22:41:24 2015 crtime: 0x5546dc54:6e6bc80c -- Sun May 3 22:41:24 2015
Size of extra inode fields: 28 EXTENTS: (0):46712815
Extents: 在最开始的ext2文件系统中,数据块都是一个一个单独管理的,inode中存有指向数据块的指针,文件占用了多少个数据块,inode里面就有多少个指针(多级),想象一下一个1G的文件,4K的块大小,那么需要(1024 * 1024)/4=262144个数据块,即需要262144个指针,创建文件的时候需要初始化这些指针,删除文件的时候需要回收这些指针,影响性能。现代的文件系统都支持Extents的功能,简单点说,Extent就是数据块的集合,以前一次分配一个数据块,现在可以一次分配一个Extent,里面包含很多数据块,同时inode里面只需要分配指向Extent的指针就可以了,从而大大减少了指针的数量和层级,提高了大文件操作的性能。
inode数量固定: 在ext2/3/4系列的文件系统中,inode的数量都是固定的,坏处是如果存很多小文件的话,有可能造成inode被用光,但磁盘还有很多剩余空间无法被使用的情况,不过它也有一个好处,就是一旦磁盘损坏,恢复起来要相对简单些,因为数据在磁盘上布局相对要固定简单。
xfs 和ext4相比,xfs不支持下面这些功能
- 不支持日志(Journal)校验码
- 不支持无日志(No Journaling)模式
- 不支持文件创建时间
- 不支持数据日志(data journal),只有元数据日志(metadata journal)
但xfs有下面这些特性
- 支持的最大文件和分区都达到了8EB
- inode动态分配,从而不受inode数量的限制,再也不用担心存储大量小文件导致inode不够用的问题了。
- 更大的xattr(extended attributes)空间,ext2/3/4及btrfs都限制xattr的长度不能超过一个块(一般是4K),而xfs可以达到64K
- 内部采用Allocation groups机制,各个group之间没有依赖,支持并发操作,在多核环境的某些场景下性能表现不错
- 提供了原生的dump和restore工具,并且支持在线dump
btrfs btrfs是一个和ZFS类似的文件系统,支持的功能非常多,据说将来会替换ext4成为Linux下的默认文件系统。这里列举一些重要的功能
- 支持的最大文件和分区达到了16EB
- 支持COW(copy on write)
- 针对小文件和SSD做了优化
- inode动态分配
- 支持子分区(Subvolumes),子分区可以单独挂载
- 支持元数据和数据的校验(crc32)
- 支持压缩,去重
- 支持多个磁盘和分区,可动态扩展
- 支持LVM,RAID的功能(有了btrfs,就不再需要lvm和软raid了)
- 增量备份和恢复
- 支持快照
- 将ext2/3/4转换成btrfs(反过来不行)
btrfs最大的缺点就是由于其COW的实现方式,导致碎片化问题比较严重,不太适合频繁写的场景,比如数据库、虚拟机的磁盘文件等。不过大部分场合不需要担心,btrfs有在线的碎片整理工具。
Linux系统启动过程
如果有一天你们公司很重要的一台Linux服务器突然启动不了了,重装系统又浪费时间,如果是启动过程有问题,那么你知道启动过程可以快速定位系统问题,很快就可以解决。
1.上电加载BIOS
首先肯定是上电,当按下计算机的电源,计算机就会首先加载BIOS系统,BIOS(Basic Input Output System)是基本输入输出系统,主要就是进行硬件检测,检测硬件能否满足运行的基本条件,叫做“硬件自检(Power-OnSelf-Test)”,简称POST,所以,计算机要顺利启动,就需要首先加载BIOS信息,在计算机还没加载操作系统的时候控制计算机。
BIOS程序一般被存放在主板ROM(只读存储芯片)中,即使关机或掉电,该程序也不会丢失。
2.加载MBR到内存
在BIOS程序的最后,将会指向计算机硬盘的MBR(Master Boot Record)主引导扇区,就是启动盘的第一个扇区,硬盘上的MBR包含基本的Boot Loader(446字节)和一个小的分区表(64字节)及分隔标识(2字节),它是一个512字节大小的扇区。
系统读取到BIOS所指向的硬盘的MBR后,就会将其load到内存(RAM)中,然后BIOS就会将控制权转交给MBR。
3.GRUB引导
在Linux资料中,被俗称GRUB的就是Boot Loader,GRUB是GRand Unified Bootloader的缩写,MBR的前446字节存放的就是GRUB程序的一部分,它是一个多重操作系统启动管理器,用来引导不同系统,GRUB是目前Linux环境中最流行的启动管理器。
如果你的计算机上配置了双操作系统,使用者就是在GRUB中进行选择究竟启动哪个操作系统。
4.加载内核(Kernel)
系统启动到这一步,首先会加载系统的Kernel,Kernel是现代操作系统的核心,直接负责管理硬件。
5.设定Inittab运行等级
在内核加载完毕后,会启动Linux操作系统第一个守护进程init,这个进程的PID是1,所有的进程都是它的子进程。
通过这个进程读取/etc/inittab文件,/etc/inittab文件的作用是设定Linux的运行等级,文件内容大致如下:
# Default runlevel. The runlevels used by RHS are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
id:3:initdefault:
...
从文件内容知道Linux系统运行等级一共有7种:
0:关机模式,运行等级为0,系统会立即关机,在系统启动后可以利用这种等级对系统进行关机操作,但是不允许将系统下次启动时的等级设定为0,否则系统将无法正常启动(启动后立即关机)。
1:单用户模式,类似于windows系统下的安全模式,具有ROOT权限。
2:无网络支持的多用户模式,顾名思义就是支持多用户登录
3:字符界面多用户模式,文本命令行界面,一般服务器都是此模式
4:保留,未使用模式
5:图形界面多用户模式,系统启动之后会进入到图形化桌面系统中
6:重新引导系统,重启模式,千万不要设置为6,和0相似。
/etc/inittab文件内容中的设定的行:
id:3:initdefault:
表示启动的层级为3,即图形界面多用户模式。一般3和5比较常用,如果需要其它等级,可以手动修改这个值。
每一个运行级别都在/etc目录下有一个对应的子目录,可以指定每一个运行级别需要加载哪些程序,rcN.d的字母d是directory的意思,表示这是一个目录。
6.加载rc.sysinit
读取完运行等级后,Linux系统就会运行第一个用户层进程:/etc/rc.d/rc.sysinit,该进程的功能是设定PATH变量、设定网络配置、启动/swap分区、设定/proc、系统函数和Selinux等等。
7.加载内核模块
完成上述流程后,会读取/etc/modules.conf文件以及/etc/modules.c目录下的文件来加载系统的内核模块。
8.启动运行级别程序
根据前面设定的运行等级,系统会执行/etc/rc0.d/到/etc/rc6.d/中相应的脚本程序,来完成相应的初始化工作和启动相应的服务,都是一些服务程序。其中以S开头表示系统即将启动的程序,如果以K开头,则代表停止该服务。S和K后紧跟的数字为启动顺序编号。
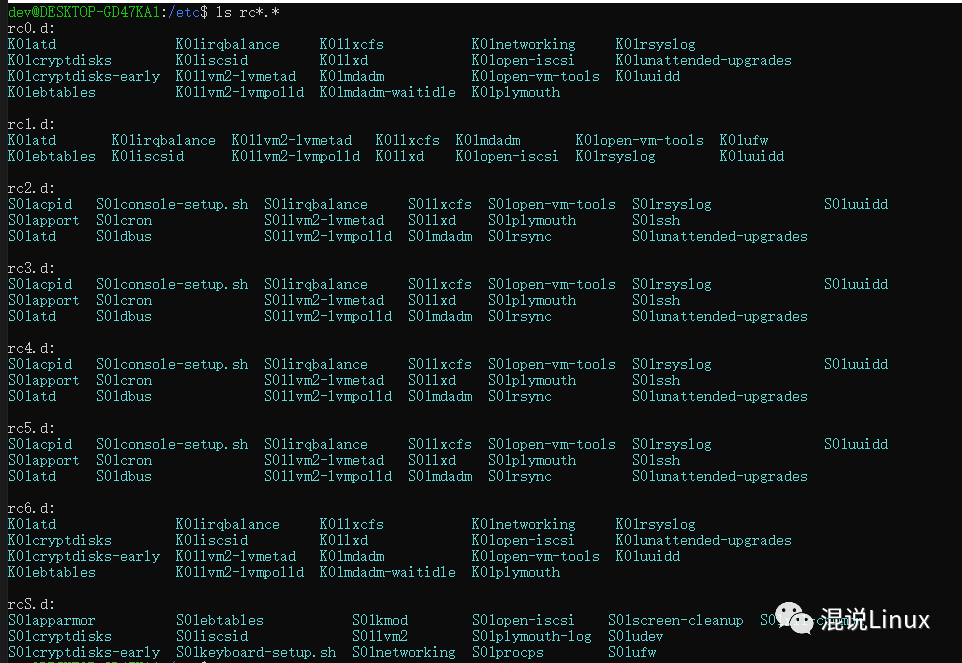 前面提到,每一个运行级别都在/etc目录下有一个对应的子目录,但是如果每一个运行级别都要执行同一个程序,那就要每一个子目录里面都要拷贝一个这个程序进去,那这样就会有一个问题:如果要修改一个程序,修改完岂不是每一个子目录里面都要修改一遍或者都要重新拷贝一遍?
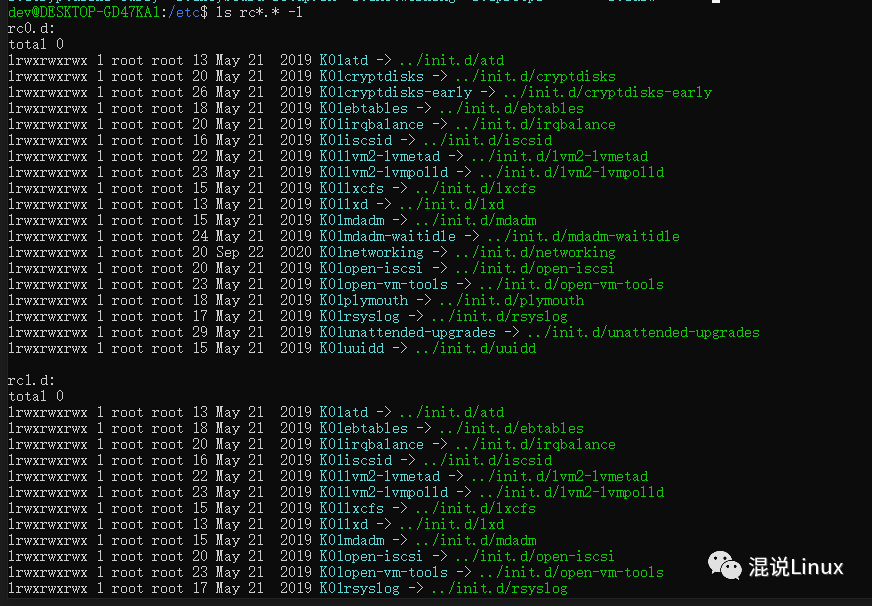
前面提到,每一个运行级别都在/etc目录下有一个对应的子目录,但是如果每一个运行级别都要执行同一个程序,那就要每一个子目录里面都要拷贝一个这个程序进去,那这样就会有一个问题:如果要修改一个程序,修改完岂不是每一个子目录里面都要修改一遍或者都要重新拷贝一遍?
所以Linux的解决办法就是每一个/etc/rcN.d目录下的文件都设为链接文件,下图中看到箭头指向/etc/init.d目录下的文件,所以实际执行的是/etc/init.d目录下的文件,只需要修改一次/etc/init.d目录下的程序就搞定了。
 9.读取rc.local文件
9.读取rc.local文件
启动完服务程序后,会读取执行/etc/rc.d/rc.local文件,我们可以对该文件设定一些关键核心业务开机自启,也就是Linux留给用户进行个性化的地方,你可以把你想要设置和启动的东西放到这里。
10.执行/bin/login
到这里,Linux系统启动结束,最后执行/bin/login程序,启动到系统登录界面,等待用户输入用户名和密码,然后就可登录到Shell终端。
Linux 内存中的缓冲区(Buffer)与缓存(Cache)
free 命令
要检查系统内存使用情况,您想到的第一个命令可能是 free ,例如:
$ free -h
total used free shared buff/cache available
Mem: 1.9G 1.0G 394M 2.6M 491M 728M
Swap: 0B 0B 0B
很明显,该输出包括了物理内存 Mem 和 Swap 的具体使用情况(如总内存、已用内存、缓存、可用内存等)。缓存是 Buffer 和 Cache 两部分的总和。
让我们看一下 free 的手册页中的 Buffer 和 Cache 定义:
buffers
Memory used by kernel buffers (Buffers in /proc/meminfo)
cache Memory used by the page cache and slabs (Cached and SReclaimable in /proc/meminfo)
buff/cache
Sum of buffers and cache
我们可以看到 free 命令的源数据实际上存储在 proc/meminfo 文件中。正如我前面提到的,/proc 是 Linux 内核提供的一个特殊的文件系统,它就像一个用户与内核交互的接口。
/proc 文件系统也是许多性能工具的最终数据源。在 man proc 中,Buffers 和 Cached 的定义如下:
Buffers %lu
Relatively temporary storage for raw disk blocks that shouldn't get tremendously large (20MB or so).
Cached %lu
In-memory cache for files read from the disk (the page cache). Doesn't include SwapCached.
...
SReclaimable %lu (since Linux 2.6.19)
Part of Slab, that might be reclaimed, such as caches.
SUnreclaim %lu (since Linux 2.6.19)
Part of Slab, that cannot be reclaimed on memory pressure.
至此,您可能认为您已经找到了我的问题的答案,“Buffer”只是用于将数据写入磁盘的缓存,“Cache”只是用于从文件中读取数据的缓存。但事实上,“Buffer”也可以用于读取,“Cache”也可以用于写入。
读取文件时数据会缓存在 Cache 中,读取磁盘时数据会缓存在 Buffer 中。
结论
在这里您应该会发现,虽然本文对 Buffer 和 Cache 进行了描述,但仍然无法涵盖所有细节。我们如今学到了以下两点:
- Buffer:既可以用作“要写入磁盘的数据缓存”,也可以用作“读取磁盘读的数据缓存”。
- Cache:既可以用作“从读取文件的页面缓存”,也可以用作“写入文件的页面缓存”。
僵尸进程和孤儿进程
通常情况下,子进程退出后,父进程会使用 wait 或 waitpid 函数进行回收子进程的资源,并获得子进程的终止状态。
但是,如果父进程先于子进程结束,则子进程成为孤儿进程。孤儿进程将被 init 进程(进程号为1)领养,并由 init 进程对孤儿进程完成状态收集工作。
而如果子进程先于父进程退出,同时父进程太忙了,无瑕回收子进程的资源,子进程残留资源(PCB)存放于内核中,变成僵尸(Zombie)进程
解决方案
对于普通进程,我们可以通过使用 kill 命令来杀死它们。kill 命令它还有几个兄弟,比如 pkill 和 killall ,虽然它们名称里都带 kill 这样杀气腾腾的字眼,但它们实际上是被设计为向一个或多个进程发送信号。
在未指定的情况下,这几个命令默认发送的是 SIGTERM 信号。
普通进程可以被 kill ,但僵尸进程是不行的。为什么?因为僵尸进程本身就已经「死」过一次了!如果还可以再「死」,那「僵尸」这个名号就没多大意义了。
僵尸进程其实已经就是退出的进程,因此无法再利用kill命令杀死僵尸进程。僵尸进程的罪魁祸首是父进程没有回收它的资源,那我们可以想办法它其它进程去回收僵尸进程的资源,这个进程就是 init 进程。
因此,我们可以直接杀死父进程,init 进程就会很善良地把那些僵尸进程领养过来,并合理的回收它们的资源,那些僵尸进程就得到了妥善的处理了。
杀死父进程时要非常小心,如果一个进程的父进程就是 PID 1 ,并且你还杀死了它,那么系统将直接重启!
raid1 raid2 raid5 raid6 raid10如何选择使用?各需要几块硬盘?
1.raid0 两块及以上的盘组成,读写性能翻倍,但是空间只有一块盘大小 2.raid1 两块及以上的盘组成,相当于mysql的主从复制,一块盘为主,一块盘为从,安全性比较高 3.raid5 数据以块为单位分布到各个磁盘上,raid5不对数据进行备份,而是把数据与其对应的奇偶校验信息存储到组成raid5的各个硬盘上面,并且奇偶校验的信息和数据分布在不同的盘,当raid5一个磁盘数据损坏后,会通过奇偶校验来恢复数据 4.raid10其实结构非常简单,首先创建2个独立的Raid1,然后将这两个独立的Raid1组成一个Raid0。
什么是Raid
raid就是冗余磁盘阵列,把多个硬磁盘驱动器按照一定的要求使整个磁盘阵列由阵列控制器管理组成一个储存系统。最开始研制目的是为了利用多个廉价的小磁盘来替代昂贵的大磁盘,以此来降低成本。而随着硬盘技术的发展,如今的磁盘阵列采用了冗余信息的方式,使得其具有数据保护的功能。
那么服务器为啥要做磁盘阵列呢?主要有两个作用:
-
提供容错功能
普通的磁盘驱动器是无法提供容错功能的,而磁盘阵列可以通过数据校验提供容错功能,服务器会将数据写入多个磁盘,如果某个磁盘发生故障时,此时仍能保证信息的可用性,重要数据不会丢失,也不会耽误服务器的正常运转。
-
提高传输速率
磁盘阵列将多个磁盘组成一个阵列,当做一个单一的磁盘使用,把数据已分段的形式存储到不同的硬盘之中,发生数据存取变动时,阵列中的相关磁盘一起工作,这就可以大幅的降低数据存储的时间,同时还能拥有更佳的空间和使用率。
常用Raid的优缺点
-
Raid 0:一块硬盘或者以上就可做raid0
优势:数据读取写入最快,最大优势提高硬盘容量,比如3块80G的硬盘做raid0,可用总容量为240G,也就是利用率是100%,速度也比较快。 缺点:无冗余能力,一块硬盘损坏,数据全无。
建议:做raid0 可以提供更好的容量以及性能,推荐对数据安全性要求不高的项目使用。
-
Raid 1:至少2块硬盘可做raid1 优势:镜像,数据安全强,一块正常运行,另外一块镜像备份数据,保障数据的安全。一块坏了,另外一块硬盘也有完整的数据,保障运行。所以这种安全性比较性最高。
缺点:性能提示不明显,做raid1之后硬盘使用率为50%,有些费硬盘。 建议:对数据安全性要求比较高的项目。可以使用Raid1。
-
Raid5:至少需要3块硬盘raid5
优势:上面提到的Raid0与Raid1的优势,raid5都兼顾。RAID5最少需要三块硬盘,通用做法是用4块硬盘,其中有一块硬盘是用来做数据冗余的,如果做RAID5的服务器上有一块硬盘坏掉了,那么我们需要把坏的盘拨下来,然后换上一块新的硬盘,系统会自动进行数据同步。
可用容量:单块磁盘容量*(n-1),n为磁盘数。
安全性能方面,RAID1最高,RAID5次于RAID1。
缺点:只允许单盘故障,一盘出现故障得尽快处理。有盘坏情况下,raid5 IO/CPU性能狂跌,此时性能烂到无以复加。
建议:盘不多,对数据安全性和性能提示都有要求,raid5是个不错选择,盘多可考虑riad10。
-
Raid6:至少需要4块硬盘做raid6 优势:raid6是在raid5的基础上为了加强数据保护而设计的。可允许损坏2块硬盘。 可用容量:C=(N-2)×D
C=可用容量 N=磁盘数量 D=单个磁盘容量。
比如4块1T硬盘做raid6可用容量是:(4-2)×1000GB=2000GB=2T
缺点:性能提升方面不明显 建议:对数据安全性要求高,性能要求不高的可选择。
-
Raid10:至少需要4块硬盘。
Raid 10是一个Raid 1与Raid0的组合体,它是利用奇偶校验实现条带集镜像,所以它继承了Raid0的快速和Raid1的安全。
是一种高成本、高可靠性、高存储性能的三高阵列技术。
优势:兼顾安全性和速度。基础4盘的情况下,raid10允许对硬盘2块故障,随着硬盘数量的提示,容错量也会相对应提升,这是raid5无法做到的。 缺点:对盘的数量要求稍高,磁盘使用率为50%。
建议:硬盘数量足够的情况,建议raid10。