部署一套完整的企业级高可用K8s集群
Master节点主要有三个服务kube-apiserver、kube-controller-manager和kube-scheduler,其中kube-controller-manager和kube-scheduler组件自身通过选择机制已经实现了高可用,所以Master高可用主要针对kube-apiserver组件,而该组件是以HTTP API提供服务,因此对他高可用与Web服务器类似,对其负载均衡即可,并且可水平扩容,但是当Master节点有增减时,如何动态配置Node节点上的负载均衡器成为了另外一个需要解决的问题,负载均衡器本身就是一个单点故障隐患,所以这里使用keepalived。
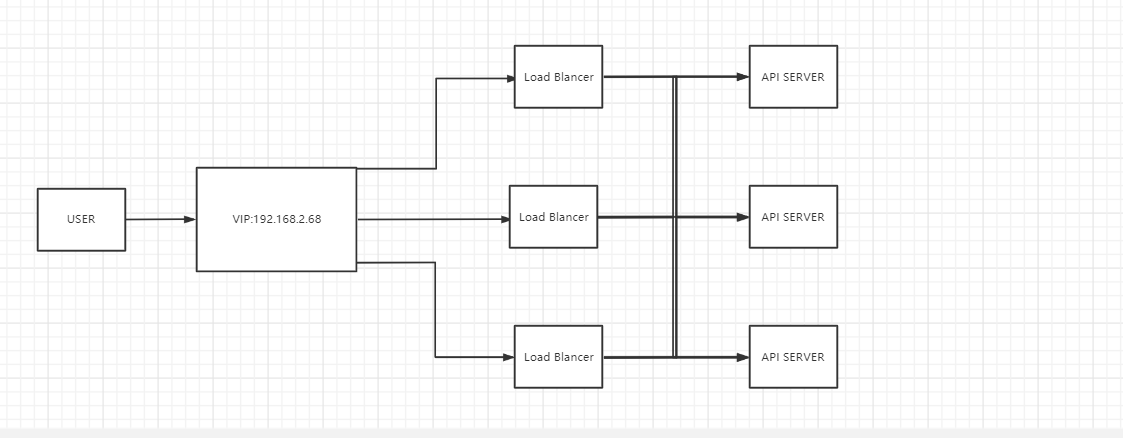
准备环境
3台Master(192.168.2.58、192.168.2.59、192.168.2.60) 3台Node(192.168.2.158、168.168.2.159、192.168.2.160) Master最小硬件配置:2核CPU、2G内存、20G硬盘 Node最小配置:1核CPU、1G内存、20G硬盘
方法
- 企业环境可以使用使用Ansible Playbook一键部署,但是个人配置不建议使用,方法太过简单,无法掌握其中内部机制。 官方项目地址 安装教程
- 使用Kubeadm手动部署,提供kubeadm init和kubeadm join,可用于快速部署Kubernetes集群,个人使用该方法。
- 二进制包方式,从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群,过程较为繁琐,但是对 kubernetes 理解也会更全面。
使用Kubeadm手动部署步骤
初始化所有节点
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
#关闭selinux
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
配置机器主机名
master1节点执行:
hostnamectl set-hostname master1 && bash
master2节点执行:
hostnamectl set-hostname master2 && bash
master3节点执行:
hostnamectl set-hostname master3 && bash
node1节点执行:
hostnamectl set-hostname node1 && bash
node2节点执行:
hostnamectl set-hostname node2 && bash
node3节点执行:
hostnamectl set-hostname node3 && bash
以下步骤所有主机都需要设置,所以建议用xshell连接全部6台主机,打开发送键输入所有会话的工具。当然也可以使用ansible。
所有主机设置/etc/hosts保证主机名能够解析,并设置github解析地址可加速国内使用,方便以后使用。
cat <<EOF >>/etc/hosts
192.168.2.58 master1
192.168.2.59 master2
192.168.2.60 master3
192.168.2.158 node1
192.168.2.159 node2
192.168.2.160 node3
52.69.186.44 github.com
185.199.110.133 raw.githubusercontent.com
EOF
互相建立免密通道
ssh-keygen
ssh-copy-id -p22 -i /root/.ssh/id_rsa.pub [email protected]
ssh-copy-id -p22 -i /root/.ssh/id_rsa.pub [email protected]
ssh-copy-id -p22 -i /root/.ssh/id_rsa.pub [email protected]
ssh-copy-id -p22 -i /root/.ssh/id_rsa.pub [email protected]
ssh-copy-id -p22 -i /root/.ssh/id_rsa.pub [email protected]
ssh-copy-id -p22 -i /root/.ssh/id_rsa.pub [email protected]
检测通道
ping -c 1 master1
ping -c 1 master2
ping -c 1 master3
ping -c 1 node1
ping -c 1 node2
ping -c 1 node3
配置阿里云yum源
rm -f /etc/yum.repos.d/*.repo
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
sed -i "/mirrors.aliyuncs.com/d" /etc/yum.repos.d/CentOS-Base.repo
sed -i "/mirrors.cloud.aliyuncs.com/d" /etc/yum.repos.d/CentOS-Base.repo
yum clean all
安装docker
yum install -y yum-utils
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install docker-ce docker-ce-cli containerd.io -y
systemctl start docker
systemctl enable docker
docker version
安装K8S
##关闭swap
swapoff -a
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
#修改Cgroup驱动
cat <<EOF> /etc/docker/daemon.json
{"exec-opts":["native.cgroupdriver=systemd"]}
EOF
systemctl restart docker
#查看驱动改为system
docker info | grep Cgroup
docker info
执行docker info如果报以下警告,执行如下命令
WARNING: bridge-nf-call-iptables is disabled WARNING:bridge-nf-call-ip6tables is disabled
cat <<EOF> /etc/sysctl.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-arptables = 1
EOF
sysctl -p
配置Kubernetes的yum仓库
cat <<EOF >/etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
EOF
注意一定要指定1.24.0以下的版本,1.24版本已经移除dockershim。
yum install -y kubelet-1.23.6 kubeadm-1.23.6 kubectl-1.23.6
systemctl enable kubelet
配置master节点
以下步骤只需在master配置,所以断掉3台node的连接。
安装nginx
脚本或者命令任选其一
bash <(curl -s -L https://cdn.jsdelivr.net/gh/yutao517/code@main/bash/one-key-nginx-install.sh)
#使用脚本安装在指定路径/usr/local/nginx,键入nginx启动
yum install epel-release -y
yum install nginx nginx-mod-stream -y
systemctl enable nginx
#命令安装设置nginx开机自启动,脚本安装不需要,已经配置。
nginx配置4层负载均衡和健康检测
worker_processes 2;
events {
worker_connections 2048;
}
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /usr/local/nginx/logs/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.2.58:6443 max_fails=1 fail_timeout=10s; # Master1 APISERVER IP:PORT
server 192.168.2.59:6443 max_fails=1 fail_timeout=10s; # Master2 APISERVER IP:PORT
server 192.168.2.60:6443 max_fails=1 fail_timeout=10s; # Master3 APISERVER IP:PORT
}
server {
listen 16443;
proxy_pass k8s-apiserver;
}
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name www.yutao.co;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
如果不做健康检查,后端有不健康节点,负载均衡器依然会先把该请求转发给该不健康节点,然后再转发给别的节点,这样就会浪费一次转发。可是,如果当后端应用重启时,重启操作需要很久才能完成的时候就会有可能拖死整个负载均衡器。此时,由于无法准确判断节点健康状态,导致请求handle住,出现假死状态,最终整个负载均衡器上的所有节点都无法正常响应请求。 max_fails=1和fail_timeout=10s,表示在单位周期为10s钟内,中达到1次连接失败,那么接将把节点标记为不可用,并等待下一个周期(同样时常为fail_timeout)再一次去请求,判断是否连接是否成功。fail_timeout为10s,max_fails为1次。
nginx -s reload
安装keepalived
yum install keepalived -y
配置keepalived高可用 关闭发送到全部,因为keepalived配置文件不一致, 最好使用非抢占模式。
master1:
cat <<EOF >/etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
nopreempt
#非抢占模式
interface ens33
virtual_router_id 51
priority 100
advert_int 1
mcast_src_ip 192.168.2.58
authentication {
auth_type PASS
auth_pass 1111
}
#虚拟IP
virtual_ipaddress {
192.168.2.68
}
track_script {
check_nginx
}
}
EOF
master2:
cat <<EOF >/etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id NGINX_BACKUP
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
nopreempt
interface ens33
virtual_router_id 51
priority 90
advert_int 1
mcast_src_ip 192.168.2.59
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.68
}
track_script {
check_nginx
}
}
EOF
master3:
cat <<EOF >/etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id NGINX_BACKUP
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
nopreempt
interface ens33
virtual_router_id 51
priority 80
advert_int 1
mcast_src_ip 192.168.2.60
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.68
}
track_script {
check_nginx
}
}
EOF
vrrp_script:指定检查 nginx 工作状态脚本(根据 nginx 状态判断是否故障转移)
cat <<EOF > /etc/keepalived/check_nginx.sh
#!/bin/bash
count=$(pidof nginx|wc -l)
if (($count==0));then
systemctl stop keepalived
else
systemctl start keepalived
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
systemctl start keepalived
systemctl enable keepalived
systemctl status keepalived
配置Supervisor管理进程 在该脚本中,如果nginx恢复并不会重启keepalived,因为只有keepalived运行的时候才会运行脚本,所以只能停止keepalived服务,而不能重启。 可以在三台master配置Supervisor,通过Supervisor管理nginx,check_nginx.sh的进程,当nginx意外被 Kill 时,Supervisor 会自动将nginx重启,nginx恢复时,Supervisor 会通过脚本自动将keepalived重启,可以很方便地做到进程自动恢复的目的,而无需自己编写 shell 脚本来管理进程。 详细步骤
检测VIP漂移现象
master1关掉nginx
nginx -s stop
查看虚拟IP是否漂移到master2
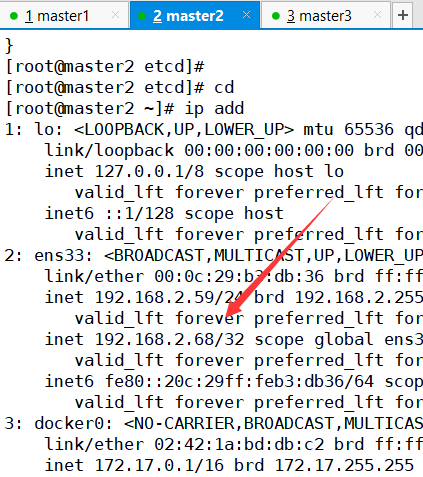
在master2关掉nginx,查看虚拟IP是否漂移到master2
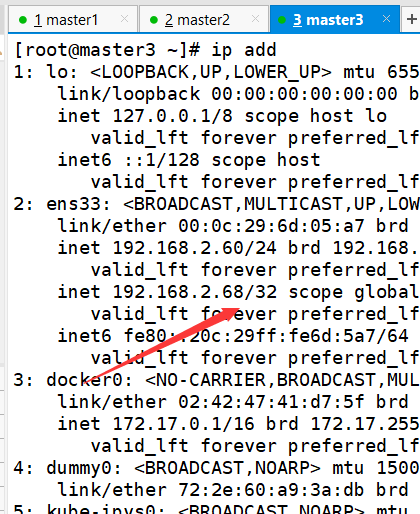
master1初始化K8S controlPlaneEndpoint:填写自己的VIP和监听端口 apiServer:填写6台主机和VIP的IP地址
cat <<EOF >kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.23.6
controlPlaneEndpoint: 192.168.2.68:16443
imageRepository: registry.aliyuncs.com/google_containers
apiServer:
certSANs:
- 192.168.2.58
- 192.168.2.59
- 192.168.2.60
- 192.168.2.158
- 192.168.2.159
- 192.168.2.160
- 192.168.2.68
networking:
podSubnet: 10.244.0.0/16
serviceSubnet: 10.10.0.0/16
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
EOF
kubeadm init --config kubeadm-config.yaml
初始化成功后配置 kubectl 的配置文件 config,相当于对 kubectl进行授权,这样 kubectl 命令可以使用这个证书对 k8s 集群进行管理。
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
添加master
把 master1 节点的证书拷贝到 master2,master3上
ssh master2 "cd /root && mkdir -p /etc/kubernetes/pki/etcd &&mkdir -p ~/.kube/"
scp /etc/kubernetes/pki/ca.crt master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.key master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.key master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.pub master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.crt master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.key master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.crt master2:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/pki/etcd/ca.key master2:/etc/kubernetes/pki/etcd/
ssh master3 "cd /root && mkdir -p /etc/kubernetes/pki/etcd &&mkdir -p ~/.kube/"
scp /etc/kubernetes/pki/ca.crt master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.key master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.key master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.pub master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.crt master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.key master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.crt master3:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/pki/etcd/ca.key master3:/etc/kubernetes/pki/etcd/
在master1上查看加入节点的命令,复制自己的
kubeadm token create --print-join-command

注意master加入的时候,后面接 –control-plane 所以应该在master2、master3输入以下命令
kubeadm join 192.168.2.68:16443 --token 8d1s8m.04a2o7as7uyvtg1h --discovery-token-ca-cert-hash sha256:747df164201cc98d4aa11d5fe0796cbe41d2a53ff84d3227781c8efdf076a47c --control-plane
添加node
在node1,node2,node3
kubeadm join 192.168.2.68:16443 --token 8d1s8m.04a2o7as7uyvtg1h --discovery-token-ca-cert-hash sha256:747df164201cc98d4aa11d5fe0796cbe41d2a53ff84d3227781c8efdf076a47c
master1安装网络插件flannel 此时集群节点状况是NotReady,所以集群需要安装网络插件flannel
wget https://raw.githubusercontent.com/yutao517/mirror/main/profile/kube-flannel.yml
#如果比较慢
wget https://download.yutao.co/mirror/kube-flannel.yml
kubectl apply -f kube-flannel.yml
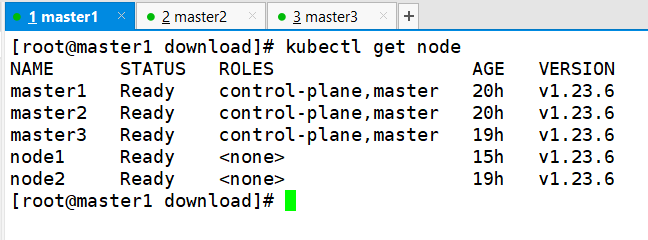
验证集群
kubectl get node
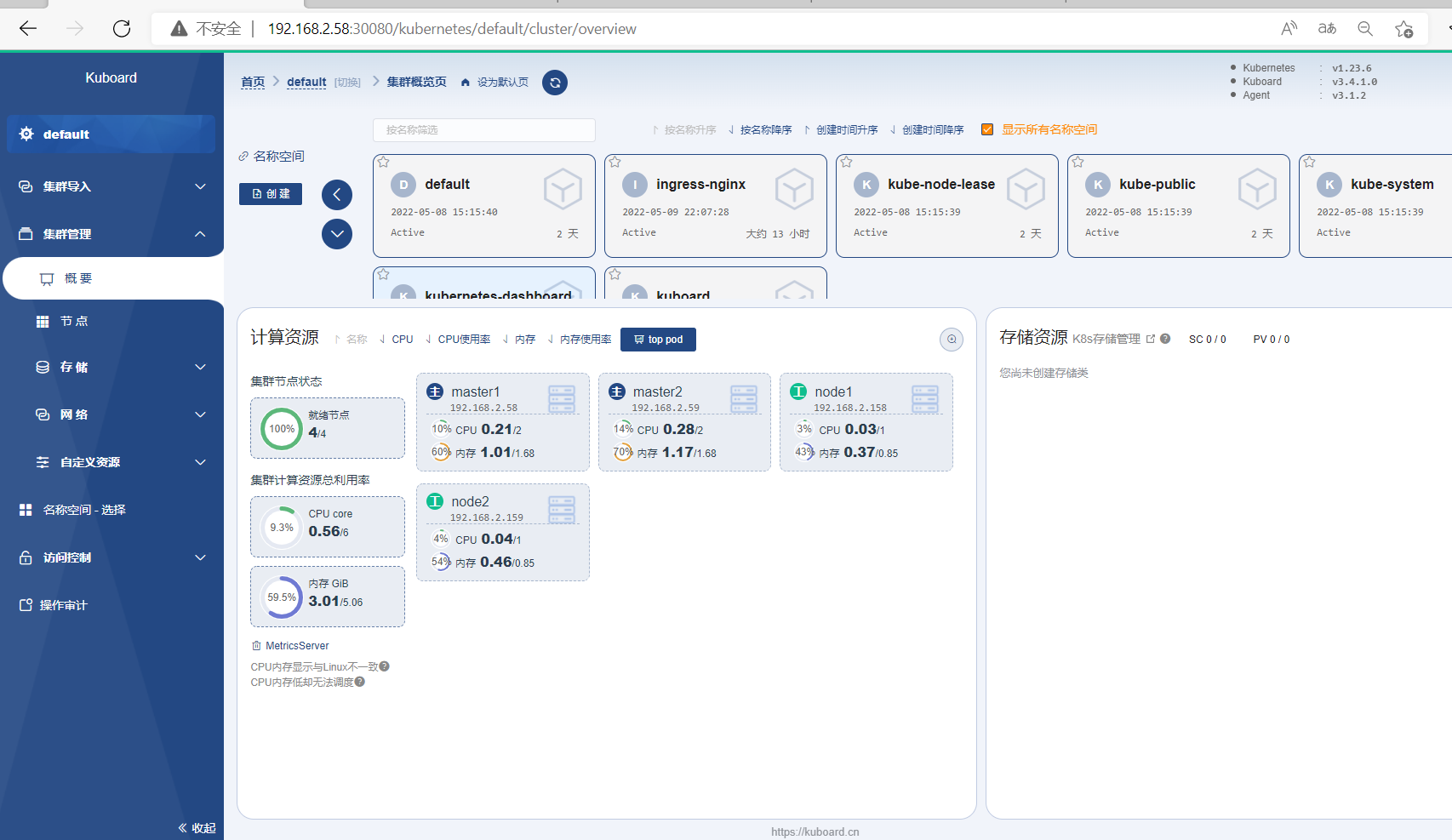
因为主机性能不佳,所以只加入了node1和node2节点
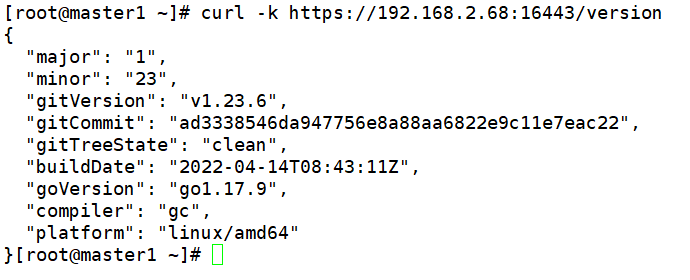
查看负载均衡器版本
curl -k https://192.168.2.68:16443/version
安装图形化界面
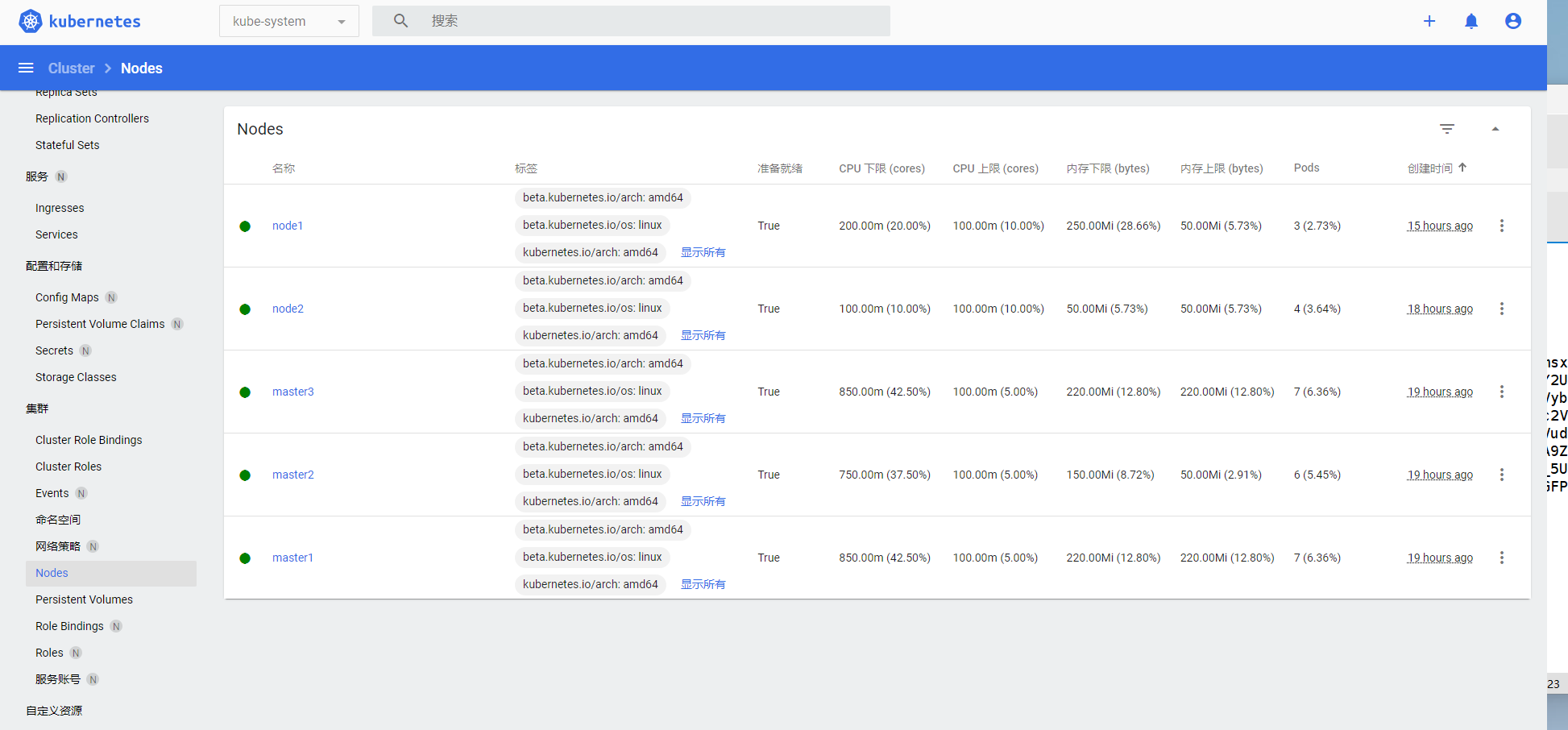
个人感觉Dashboard的效果不如Kuboard效果明显些
提前部署Metrics-Serve,否则无法采集到数据
kubectl apply -f https://download.yutao.co/mirror/components.yaml
Prometheus—Alertmanager+Grafana实现企业微信告警和Webhook机器人(钉钉机器人和微信机器人)告警